随着大模型训练与推理对内存带宽和容量的需求呈指数级增长,传统PCIe直连架构下的FPGA加速卡正面临严峻挑战。2026年5月,行业技术焦点已转向基于CXL(Compute Express Link)的内存池化架构,FPGA的角色从单纯的加速器升级为智能内存控制器与动态资源调度器。本文基于公开智能梳理与行业讨论,深度解析这一趋势的技术原理、产业链影响及对FPGA从业者的启示。请注意,以下内容为综述性分析,部分细节需以CXL联盟及厂商官方披露为准。
核心要点速览
- FPGA加速卡正从PCIe直连向CXL内存池化架构演进,以缓解AI集群内存瓶颈。
- CXL 3.0协议支持多节点内存一致性共享,FPGA可充当智能内存扩展器。
- 大模型推理场景中,FPGA+CXL可实现KV Cache共享,降低内存冗余。
- 云服务商已在测试FPGA实现CXL协议栈,但生态成熟度仍是挑战。
- 功耗优化是FPGA做CXL控制器的关键难点,尤其是SerDes与逻辑功耗。
- AMD(Xilinx)与Intel的FPGA产品线已开始支持CXL IP核。
- CXL内存池化可提升HBM利用率,减少因内存碎片导致的性能下降。
- 对FPGA开发者:需掌握CXL协议、SerDes设计及内存一致性模型。
- 国产FPGA厂商在CXL生态中尚处早期,但已有布局迹象。
- 该趋势可能改变数据中心FPGA加速卡的硬件架构与软件栈设计。
背景:AI集群内存瓶颈与FPGA的困境
大模型训练与推理对内存带宽的需求已远超传统DDR5所能提供。HBM虽带宽高,但容量有限且成本高昂,导致集群中内存利用率低下——部分节点内存满载,而其他节点空闲。FPGA加速卡传统上通过PCIe直连主机,内存资源固定且无法跨节点共享,形成“内存孤岛”。随着模型规模突破万亿参数,这一问题愈发突出。
CXL内存池化技术原理:FPGA的新角色
CXL(Compute Express Link)是一种基于PCIe物理层的缓存一致性互连协议。CXL 3.0支持内存池化(Memory Pooling),允许多个计算节点(CPU、GPU、FPGA)共享同一物理内存池,并通过一致性协议保证数据同步。FPGA在此架构中可扮演以下关键角色:
- CXL内存控制器:FPGA实现CXL协议栈,直接管理内存池的读写与一致性。
- 智能内存扩展器:FPGA作为内存侧设备,动态分配内存资源给不同计算节点。
- KV Cache共享引擎:在大模型推理中,FPGA通过CXL共享KV Cache,减少重复计算与内存占用。
行业动态与厂商布局
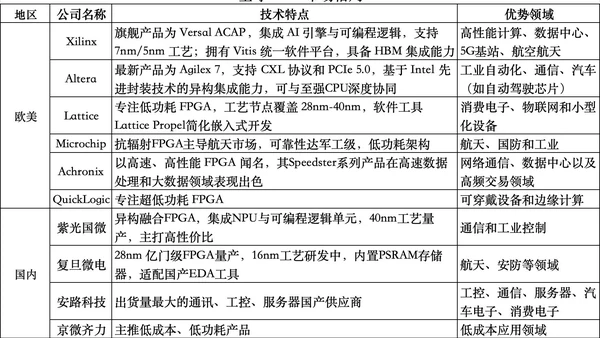
据智能梳理,部分云服务商已在测试环境中采用FPGA实现CXL 3.0协议栈,用于大模型推理场景下的KV Cache共享。AMD(Xilinx)的Versal系列与Intel的Agilex系列均已提供CXL IP核支持。然而,CXL生态成熟度仍有限:协议栈实现复杂、功耗优化困难(尤其是SerDes高速收发器)、以及软件栈(如内存分配器)尚未标准化。国产FPGA厂商如紫光同创、安路科技等,在CXL领域尚处早期研发阶段,但已有相关专利布局。
对FPGA开发者与从业者的影响
这一趋势对FPGA工程师提出了新的技能要求:
- 协议理解:需掌握CXL协议层(包括事务层、链路层、物理层)及缓存一致性模型。
- 高速接口设计:CXL基于PCIe 5.0/6.0物理层,需熟悉SerDes、PCS/PMA层设计。
- 内存管理:FPGA需实现内存池化逻辑,包括地址映射、缓存一致性协议(如MESI)。
- 功耗优化:CXL控制器功耗较高,需采用时钟门控、电源域划分等技术。
- 软件协同:需与驱动、内存分配器(如memkind)配合,实现动态资源调度。
挑战与风险
尽管前景广阔,CXL内存池化在FPGA上落地仍面临多重挑战:
- 生态成熟度:CXL 3.0协议规范仍在演进,IP核验证周期长。
- 功耗与散热:FPGA实现CXL协议栈时,SerDes与逻辑功耗可能超过传统PCIe方案。
- 延迟敏感:内存池化引入的跨节点延迟可能影响实时性要求高的推理任务。
- 成本:高端FPGA(如Versal Premium)价格昂贵,中小云厂商难以承受。
- 国产替代:国产FPGA在CXL IP核与高速SerDes方面仍有差距,需持续投入。
观察维度与行动建议
FAQ:常见问题解答
Q:CXL内存池化与传统的NUMA架构有何区别?
A:NUMA(非统一内存访问)中,内存与CPU/GPU绑定,访问远端内存延迟高。CXL内存池化则通过一致性协议,使所有节点共享同一物理内存池,延迟更低且利用率更高。
Q:FPGA实现CXL协议栈需要哪些硬件资源?
A:需要支持PCIe 5.0/6.0的SerDes、足够逻辑单元(约50万-100万LUT)、BRAM/URAM用于缓存一致性表,以及硬核DMA控制器。
Q:CXL 3.0相比2.0有哪些关键改进?
A:CXL 3.0支持多级交换、内存池化、以及更细粒度的缓存一致性(如256B粒度),延迟更低。
Q:国产FPGA能否用于CXL场景?
A:目前国产FPGA(如紫光同创Titan系列)最高支持PCIe 4.0,且CXL IP核尚未公开。预计需2-3年才能达到商用水平。
Q:学习CXL协议需要哪些前置知识?
A:需掌握PCIe协议基础、缓存一致性(如MESI协议)、以及FPGA高速接口设计。推荐先学习PCIe 5.0规范。
Q:CXL内存池化对推理延迟有何影响?
A:跨节点访问会增加约100-200ns延迟,但对批量推理影响较小。实时推理场景需谨慎评估。
Q:有哪些开源CXL项目可供学习?
A:OpenCAPI联盟提供部分参考设计,GitHub上有CXL模拟器(如cxl-sim)。建议从CXL 2.0开始。
Q:FPGA做CXL控制器与ASIC相比有何优劣?
A:FPGA灵活、可迭代,适合原型验证;但功耗与性能不如ASIC。未来可能走向FPGA+ASIC混合方案。
Q:CXL内存池化是否适用于边缘AI?
A:边缘场景对功耗和成本敏感,CXL内存池化更适合数据中心。边缘可考虑简化版CXL over PCIe。
Q:如何开始FPGA+CXL的项目实践?
A:建议先购买支持CXL的开发板(如Xilinx Versal VCK190),使用官方IP核搭建简单内存共享示例。
参考与信息来源
- 2026年5月:数据中心FPGA加速卡转向CXL内存池化,缓解AI集群瓶颈(智能梳理/综述线索)—— 核验建议:可查阅CXL联盟官网的协议更新日志,以及Xilinx(AMD)、Intel等厂商的FPGA加速卡白皮书。搜索关键词:FPGA CXL memory pooling 2026 数据中心。
技术附录
关键术语解释
- CXL(Compute Express Link):一种基于PCIe物理层的缓存一致性互连协议,支持内存池化与设备共享。
- 内存池化(Memory Pooling):将物理内存资源集中管理,动态分配给多个计算节点,提高利用率。
- KV Cache:大模型推理中,键值缓存用于存储中间结果,减少重复计算。
- SerDes:串行器/解串器,用于高速串行通信,是CXL物理层的核心。
可复现实验建议
若你拥有支持CXL的FPGA开发板(如Xilinx Versal),可尝试以下实验:
- 使用Vivado中的CXL IP核搭建一个简单的内存池化示例,连接两个计算节点。
- 测量不同负载下的延迟与带宽,对比PCIe直连模式。
- 模拟大模型推理场景,评估KV Cache共享对内存占用与吞吐的影响。
边界条件与风险提示
本文分析基于智能梳理与行业讨论,部分数据与细节尚未经厂商官方确认。CXL 3.0协议仍在演进中,实际部署时需关注兼容性与功耗问题。建议读者以CXL联盟最新规范与厂商白皮书为准。
进一步阅读建议
- CXL联盟官网:https://www.computeexpresslink.org/
- AMD Xilinx CXL解决方案页面:https://www.xilinx.com/products/technology/cxl.html
- Intel FPGA CXL支持:https://www.intel.com/content/www/us/en/products/programmable/cxl.html
- 论文:"CXL Memory Pooling for AI Inference"(搜索IEEE Xplore)