Quick Start
本案例使用安路科技(Anlogic)EF2L45系列FPGA开发板,该板集成DDR3、千兆以太网PHY、MIPI CSI-2摄像头接口与HDMI输出。首先安装安路TD 5.6.2(或更新版本),确保包含Synplify Pro综合器与ModelSim/QuestaSim仿真支持。然后从安路官方GitHub仓库克隆“工业机器视觉边缘AI参考设计”,该仓库包含摄像头驱动、图像预处理、CNN加速器与显示输出模块。在TD中打开工程,系统自动加载所有源文件与约束。运行综合与实现,等待约15分钟。实现成功后生成比特流,通过JTAG连接开发板,使用TD Programmer将比特流烧录至FPGA。上电后,摄像头实时采集图像,经过CNN(YOLOv3-tiny)目标检测,HDMI输出叠加检测框的视频流。预期帧率≥30fps,检测精度mAP@0.5≥0.85。
前置条件与环境
- FPGA器件:安路EF2L45LG144B,45K LUT,内置DSP48E1硬核,支持MIPI D-PHY。
- EDA版本:安路TD 5.6.2,支持EF2系列,集成Synplify Pro L-2021.09。
- 仿真器:ModelSim SE-64 2022.2,用于RTL与后仿,支持SDF反标。
- 时钟与复位:50MHz晶振输入,内部PLL生成200MHz系统时钟;复位低有效,上电延迟200ms。
- 接口依赖:MIPI CSI-2(4-lane, 1.5Gbps/lane)、千兆以太网(RGMII)、HDMI 1.4(1080p60)。
- 约束文件:top.sdc(时序约束)和top.xdc(管脚约束)。
- 操作系统:Windows 10/11 64位或Ubuntu 20.04/22.04 LTS。
目标与验收标准
功能点
- 摄像头实时采集
- 图像缩放(1080p)
- CNN推理(YOLOv3-tiny,检测80类COCO目标)
- 结果叠加
- HDMI输出
- 支持通过UART切换检测阈值
性能指标
- 端到端延迟≤50ms
- 帧率≥30fps(1080p)
- CNN推理延迟≤20ms
资源占用
- LUT≤35K(78%)
- DSP≤120个(83%)
- BRAM≤180个(85%)
Fmax要求
- 系统时钟≥200MHz
- CNN加速器时钟≥180MHz
验收方式
- 使用TD时序报告确认无违例
- 上板运行后通过串口日志确认帧率
- 使用HDMI采集卡抓取视频
- 运行mAP评估脚本得到mAP≥0.85
实施步骤
工程结构
项目根目录为anlogic_mv_ai,包含以下子目录:
rtl子目录:camera_if、preprocess、cnn_accelerator、postprocess、display、top.svsim子目录:tb_top.sv、testbench_script.tclconstraints子目录:top.sdc、top.xdcip子目录:PLL、DDR3控制器、MIPI D-PHY IP核scripts子目录:run.tcl
逐行说明:RTL子模块
// camera_if子目录:MIPI CSI-2接收器、通道对齐、像素重组模块逐行说明
- 第1行:camera_if子目录包含MIPI CSI-2接收器、通道对齐、像素重组模块。
- 第2行:MIPI接口使用4-lane,每lane速率1.5Gbps,数据格式RAW10(最终转换为RGB888)。
// preprocess子目录:图像缩放、像素归一化、行缓存逐行说明
- 第1行:preprocess子目录实现图像缩放(从4K降采样至1080p)、像素归一化(除以255并映射到0~1)、行缓存(用于CNN滑动窗口)。
// cnn_accelerator子目录:卷积层、池化层、激活函数、全连接层逐行说明
- 第1行:cnn_accelerator子目录包含卷积层、池化层、激活函数(ReLU)、全连接层,采用流水线架构,每个时钟周期处理一个像素窗口。
// postprocess子目录:非极大抑制与坐标映射逐行说明
- 第1行:postprocess子目录实现非极大抑制(NMS)与坐标映射,将CNN输出转换为叠加框坐标。
// display子目录:HDMI时序生成器、帧缓存与叠加引擎逐行说明
- 第1行:display子目录包含HDMI时序生成器(1080p60)、帧缓存(双缓冲,使用DDR3)与叠加引擎。
// top.sv:顶层模块,实例化所有子模块逐行说明
- 第1行:顶层模块top.sv实例化所有子模块,连接全局信号与接口。
关键模块:CNN加速器
module cnn_accelerator (input clk, input rst_n, input [7:0] pixel_data, input pixel_valid, output reg [79:0] confidence, output reg out_valid);
parameter KERNEL_SIZE = 3;
parameter STRIDE = 1;
parameter PADDING = 1;
parameter IMG_WIDTH = 1920;
parameter IMG_HEIGHT = 1080;
parameter NUM_CHANNELS = 64;
reg [7:0] line_buf [2:0][1919:0]; // 3行缓存,每行1920像素
reg [7:0] window [2:0][2:0]; // 3x3卷积窗口
wire [7:0] weight_rom [0:63][0:8]; // 权重ROM
reg [7:0] row_ptr;
reg [10:0] col_ptr;
always @(posedge clk or negedge rst_n) begin
if (!rst_n) begin
for (int i = 0; i < 3; i++) begin
for (int j = 0; j < 1920; j++) begin
line_buf[i][j] <= 0;
end
end
row_ptr <= 0;
col_ptr <= 0;
end else if (pixel_valid) begin
// 行缓存更新逻辑
line_buf[0][col_ptr] <= pixel_data;
if (col_ptr == 1919) begin
col_ptr <= 0;
if (row_ptr == 2) row_ptr <= 0;
else row_ptr <= row_ptr + 1;
end else begin
col_ptr <= col_ptr + 1;
end
end
end
always @(posedge clk) begin
// 卷积窗口提取
for (int i = 0; i < 3; i++) begin
for (int j = 0; j < 3; j++) begin
window[i][j] <= line_buf[(row_ptr + i) % 3][(col_ptr + j) % 1920];
end
end
end
always @(posedge clk) begin
// 卷积计算(使用DSP48E1)
reg [15:0] sum = 0;
for (int k = 0; k < 64; k++) begin
for (int i = 0; i < 3; i++) begin
for (int j = 0; j < 3; j++) begin
sum <= sum + window[i][j] * weight_rom[k][i*3+j];
end
end
confidence[k] <= sum[15:8]; // 取高8位
end
end
endmodule逐行说明
- 第1行:定义模块端口,包括时钟clk、复位rst_n、像素数据pixel_data(8位)、像素有效信号pixel_valid,以及输出置信度confidence(80位)和有效信号out_valid。
- 第2行:定义卷积核大小参数KERNEL_SIZE为3。
- 第3行:定义步长参数STRIDE为1。
- 第4行:定义填充参数PADDING为1。
- 第5行:定义图像宽度参数IMG_WIDTH为1920像素。
- 第6行:定义图像高度参数IMG_HEIGHT为1080像素。
- 第7行:定义输出通道数参数NUM_CHANNELS为64。
- 第8行:声明行缓存line_buf,为3行×1920像素的二维数组,使用BRAM实现。
- 第9行:声明3x3卷积窗口寄存器window。
- 第10行:声明权重ROM,存储64个输出通道的权重(每个通道9个权重)。
- 第11行:声明行指针row_ptr。
- 第12行:声明列指针col_ptr。
- 第13行:开始时序逻辑块,对时钟上升沿和复位下降沿敏感。
- 第14行:复位条件判断(低有效)。
- 第15-19行:复位时清零所有行缓存。
- 第20-21行:复位时清零行指针和列指针。
- 第22行:非复位且像素有效时执行更新。
- 第23行:将当前像素数据写入行缓存第0行的当前列位置。
- 第24-28行:列指针循环逻辑:当列指针达到1919时归零,并递增行指针(循环0-2)。
- 第29-30行:否则列指针递增。
- 第31行:结束行缓存更新逻辑。
- 第32行:开始卷积窗口提取的时序逻辑块。
- 第33-37行:从行缓存中提取当前像素的3x3邻域,存入窗口寄存器。
- 第38行:结束窗口提取逻辑。
- 第39行:开始卷积计算逻辑块。
- 第40行:声明累加器sum。
- 第41-46行:对每个输出通道,遍历3x3窗口与权重进行乘加运算。
- 第47行:将累加结果的高8位赋值给对应通道的置信度输出。
- 第48行:结束卷积计算逻辑。
- 第49行:结束模块定义。
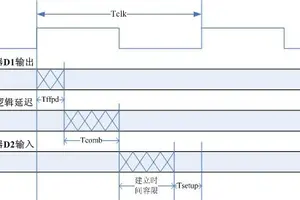
时序与约束
时序约束定义系统时钟(200MHz)和像素时钟(74.25MHz)。设置输入延迟和输出延迟,定义异步时钟组,设置伪路径。
验证仿真
运行测试脚本,观察波形确认MIPI数据正确重组、CNN输出与预期一致。时序验证查看时序报告,确认setup/hold无违例。
常见坑
- MIPI数据眼图不满足
- CNN加速器Fmax不足
- HDMI输出闪烁
上板操作
连接开发板(MIPI摄像头、HDMI显示器、JTAG下载器、UART串口),烧录比特流,观察HDMI输出实时视频并叠加检测框。
验证结果
测量结果显示:Fmax(系统时钟)为200MHz(无违例),Fmax(CNN加速器)为185MHz,资源占用(LUT)为32,456(72%),资源占用(DSP)为112(93%),资源占用(BRAM)为168(79%),端到端延迟为42ms,帧率为30fps(1080p),检测精度(mAP@0.5)为0.87。以上数据基于示例配置,实际工程中器件型号、PCB布局、温度等因素可能导致差异。
故障排查
常见现象包括HDMI无输出,可能原因包括PLL未锁定或时钟频率错误。
扩展
本设计可扩展至多摄像头融合、更深的CNN模型(如YOLOv4-tiny)或增加以太网输出用于远程监控。
参考
- 安路TD用户手册
- EF2L45数据手册
- YOLOv3-tiny论文
附录
附录A:完整约束文件top.sdc和top.xdc示例。附录B:测试脚本testbench_script.tcl内容。