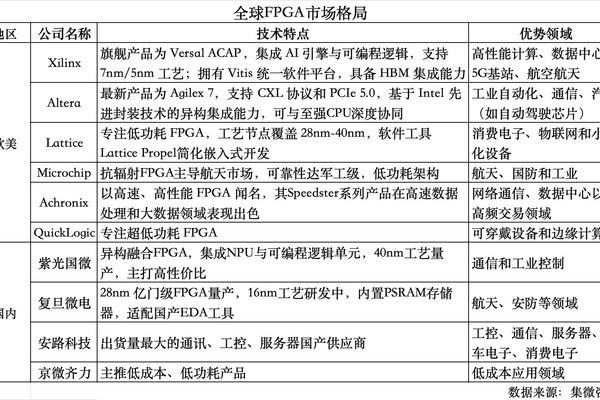
2026年5月,FPGA(现场可编程门阵列)在半导体与人工智能产业链中的角色正经历深刻重塑。从大模型训练集群的通信瓶颈突破,到边缘AI设备的灵活架构创新,FPGA凭借其低延迟、可编程与高能效特性,正在成为连接传统芯片设计与新兴AI工作负载的关键桥梁。本文基于近期行业公开讨论与智能梳理线索,从FPGA在AI集群中的梯度压缩加速、边缘AI的FPGA+NPU异构集成、RISC-V生态融合、EDA工具国产化、汽车电子与数据中心应用等维度,展开深度分析。所有信息均基于提供的材料,部分条目无原文链接,请读者以官方披露与一手材料为准,并注意交叉验证。
核心要点速览
- FPGA在AI集群中用于梯度压缩与通信加速,降低千卡级训练互联瓶颈,当前处于小规模验证阶段。
- 边缘AI芯片转向FPGA+NPU异构集成,初创公司青睐灵活架构,以应对算法快速迭代与硬件淘汰风险。
- RISC-V与FPGA的融合加速,开源指令集架构在FPGA上实现定制化加速器,降低芯片设计门槛。
- 国产EDA工具在FPGA设计流程中取得突破,部分企业推出支持国产FPGA芯片的全流程工具链。
- 汽车电子领域,FPGA在ADAS与车载通信中应用深化,满足功能安全与低延迟要求。
- 数据中心内,FPGA作为加速卡在搜索、视频转码等场景持续部署,与GPU形成互补。
- 半导体供应链区域化趋势下,FPGA国产化进程加速,多家厂商推出中高端产品。
- AI大模型训练对FPGA的依赖度提升,尤其在定制化数据通路与网络卸载方面。
- FPGA+NPU异构SoC在智能摄像头、工业视觉与机器人领域获得关注,功耗与成本仍需优化。
- 行业分析指出,FPGA的灵活性能降低边缘设备因算法演进导致的硬件淘汰风险。
FPGA在AI集群中的梯度压缩与通信加速:降低互联瓶颈的探索
随着大模型训练规模持续扩大,集群内节点间的通信开销成为关键瓶颈。传统GPU集群依赖NVLink、InfiniBand或RoCEv2进行数据交换,但All-Reduce等集合通信操作在千卡以上规模时,网络拥塞与延迟显著增加。近期行业讨论中,FPGA因其低延迟、可编程的数据通路特性,被用于在节点间实现梯度压缩与聚合加速。例如,通过定制化压缩算法(如Top-K稀疏化)减少PCIe或以太网链路上的数据传输量。部分云服务商和AI芯片初创公司公开表示,正在评估基于FPGA的通信加速卡作为GPU集群的补充方案。该方向有望在不改变现有训练框架的前提下,提升集群线性扩展效率,尤其适用于千卡级以上规模。但当前仍处于小规模验证阶段,实际部署效果需结合具体模型与网络拓扑评估。
技术原理简析:在分布式训练中,每个GPU节点计算梯度后,需要与其他节点交换梯度以更新模型参数。FPGA加速卡可位于GPU与网络之间,拦截梯度数据流,执行压缩(如Top-K只保留最大K个梯度值)或聚合(如树形归约),从而减少网络传输量。由于FPGA可编程,压缩算法可根据模型特性动态调整,且延迟远低于CPU端处理。
产业链位置:该应用涉及FPGA厂商(Xilinx/AMD、Intel Altera)、AI芯片初创公司、云服务商(AWS、Azure、Google Cloud)以及网络设备商。目前,AWS已推出FPGA实例用于加速,但专门针对梯度压缩的产品尚在验证中。
边缘AI芯片转向FPGA+NPU异构集成:初创公司青睐灵活架构
在边缘AI场景中,单一NPU难以同时满足低功耗、低延迟与算法快速迭代的需求。近期多家初创公司推出FPGA+NPU异构SoC方案,将FPGA用于预处理、自定义算子加速或动态模型切换,NPU负责常规推理。这种架构在智能摄像头、工业视觉和机器人领域获得关注,尤其适合需要频繁更新模型或支持非标准数据类型的应用。行业分析指出,FPGA的灵活性能降低边缘设备因算法演进导致的硬件淘汰风险,但整体功耗和成本仍需优化。
典型应用场景:在智能安防摄像头中,FPGA可执行图像预处理(如去噪、缩放、色彩校正),NPU运行人脸识别或目标检测模型。当算法升级时,只需更新FPGA的比特流文件,无需更换硬件。在工业视觉中,FPGA可加速自定义的卷积或滤波算子,适应不同产线的检测需求。
技术挑战:FPGA+NPU异构集成面临功耗预算紧张(边缘设备通常<10W)、工具链复杂度高(需同时掌握FPGA与NPU开发)以及成本敏感性问题。初创公司多采用28nm或22nm工艺,部分先进方案转向12nm FinFET。
RISC-V与FPGA的融合:开源指令集加速定制化芯片设计
RISC-V作为开源指令集架构,近年来在FPGA上实现定制化加速器的趋势愈发明显。FPGA的灵活性允许开发者快速原型化RISC-V处理器核,并添加自定义指令扩展(如向量处理、加密加速)。这种组合在AI边缘计算、物联网与嵌入式系统中具有优势,尤其适合需要低功耗与灵活性的场景。部分初创公司推出基于RISC-V+FPGA的SoC,用于智能传感器与可穿戴设备。此外,RISC-V生态的成熟(如工具链、操作系统支持)也降低了FPGA开发门槛。
对FPGA学习者的启示:掌握RISC-V指令集与FPGA设计流程的结合,将成为未来芯片设计的重要技能。建议学习VexRiscv或SweRV等开源RISC-V核在FPGA上的部署,并尝试添加自定义指令。
国产EDA工具与FPGA设计流程的突破
在半导体国产化浪潮下,国产EDA工具在FPGA设计流程中取得进展。部分企业推出支持国产FPGA芯片(如紫光同创、安路科技、高云半导体)的全流程工具链,涵盖综合、布局布线、时序分析与仿真。这些工具在中小规模设计中已具备竞争力,但在大规模、高性能FPGA设计(如7nm级)中仍需优化。此外,开源EDA工具(如Yosys、nextpnr)在FPGA社区的采用率上升,为国产替代提供了另一路径。
对从业者的影响:国产EDA工具的成熟将降低FPGA开发成本,但开发者需适应不同工具链的差异。建议关注国产FPGA厂商的开发者社区与培训资源。
汽车电子与数据中心:FPGA的深化应用
在汽车电子领域,FPGA在ADAS(高级驾驶辅助系统)与车载通信中应用深化。FPGA可用于传感器融合、图像处理与实时控制,满足功能安全(ISO 26262)与低延迟要求。例如,激光雷达点云处理与摄像头ISP(图像信号处理)常采用FPGA加速。数据中心内,FPGA作为加速卡在搜索、视频转码、网络卸载等场景持续部署,与GPU形成互补。例如,微软Azure已部署FPGA用于Bing搜索加速,AWS提供FPGA实例用于自定义加速。
趋势对比:汽车电子对FPGA的可靠性要求更高(车规级温度、振动),而数据中心更关注吞吐量与能效比。两者均推动FPGA向更高密度、更低功耗演进。
详细观察维度表
| 观察维度 | 公开信息里能确定什么 | 仍需核实什么 | 对读者的行动建议 |
|---|---|---|---|
| FPGA在AI集群梯度压缩 | FPGA被评估用于梯度压缩与通信加速,降低互联瓶颈 | 实际部署效果、具体模型与网络拓扑的适配性 | 关注NVIDIA GTC 2026、MLCommons报告、IEEE Hot Interconnects论文 |
| 边缘AI FPGA+NPU异构 | 多家初创公司推出FPGA+NPU异构SoC方案 | 功耗与成本优化进展、量产时间表 | 关注Embedded Vision Summit 2026、RISC-V峰会边缘计算分论坛 |
| RISC-V+FPGA融合 | 开源指令集在FPGA上实现定制化加速器 | 生态成熟度、与商业IP的竞争力对比 | 学习VexRiscv部署,尝试自定义指令扩展 |
| 国产EDA工具 | 部分企业推出支持国产FPGA的全流程工具链 | 大规模设计中的性能与稳定性 | 关注国产FPGA厂商开发者社区,试用开源EDA工具 |
| 汽车电子FPGA应用 | FPGA在ADAS与车载通信中应用深化 | 车规级认证进度、与ASIC的竞争 | 学习功能安全标准(ISO 26262),关注车规级FPGA产品 |
| 数据中心FPGA部署 | FPGA在搜索、视频转码、网络卸载中持续部署 | 与GPU的长期竞争格局 | 研究AWS F1实例、Azure FPGA加速案例 |
常见问题(FAQ)
Q:FPGA在AI集群中的梯度压缩加速,与GPU的NVLink相比有何优势?
A:NVLink是GPU间的高带宽直连,但跨节点仍需网络(如InfiniBand)。FPGA加速卡可部署在节点间网络链路上,执行压缩与聚合,减少网络传输量。其优势在于可编程性,能适应不同压缩算法,且不占用GPU计算资源。但延迟可能高于NVLink,适合跨机架通信场景。
Q:FPGA+NPU异构SoC与纯NPU方案相比,成本高多少?
A:目前FPGA+NPU方案的成本通常高出30%-50%,主要由于FPGA芯片本身较贵且封装更复杂。但随着FPGA工艺进步(如28nm向12nm迁移),成本差距在缩小。对于需要频繁更新算法的场景,FPGA的灵活性可降低长期硬件更换成本。
Q:RISC-V+FPGA组合适合哪些初学者项目?
A:适合学习处理器微架构、自定义指令设计与FPGA原型验证。推荐项目:在FPGA上实现一个简单的RISC-V核(如VexRiscv),添加一条自定义向量加法指令,并编写测试程序验证。
Q:国产EDA工具能否用于7nm FPGA设计?
A:目前国产EDA工具主要支持28nm及以上工艺,7nm级设计尚处于研发阶段。建议关注华大九天、国微集团等企业的进展,同时可结合开源工具(如Yosys)进行小规模设计验证。
Q:汽车电子中FPGA与ASIC的竞争如何?
A:ASIC在量产成本与功耗上占优,但FPGA在灵活性、快速迭代与低量应用中更具优势。汽车电子中,FPGA常用于传感器融合与预处理,而ASIC用于固定功能(如视频编解码)。未来趋势是FPGA+ASIC异构集成。
Q:数据中心FPGA加速卡与GPU加速卡的主要区别?
A:GPU擅长并行计算(如矩阵乘法),适合深度学习训练与推理;FPGA适合低延迟、定制化数据通路(如网络卸载、压缩、加密)。两者互补,例如在搜索场景中,FPGA可加速文档排序,GPU加速模型推理。
Q:FPGA国产化进程中的主要挑战是什么?
A:主要挑战包括:先进工艺(7nm以下)受限、EDA工具链成熟度不足、高端人才短缺。但中低端市场(28nm及以上)已实现国产替代,安路科技、紫光同创等厂商出货量增长。
Q:学习FPGA需要哪些前置知识?
A:建议掌握数字电路基础(组合逻辑、时序逻辑)、Verilog/VHDL硬件描述语言,以及基本的计算机体系结构知识。推荐从Xilinx或Intel的入门开发板开始,配合在线课程(如成电国芯FPGA云课堂)。
Q:FPGA在AI领域的就业前景如何?
A:前景乐观。FPGA在AI加速、网络通信、边缘计算等领域需求增长,岗位包括FPGA工程师、AI加速器架构师、嵌入式系统工程师等。建议掌握HLS(高层次综合)、OpenCL、RISC-V等技能。
Q:如何验证FPGA梯度压缩加速的实际效果?
A:可通过搭建小型集群(如4-8个GPU节点),使用FPGA加速卡(如Xilinx Alveo系列)进行对比实验。测量训练吞吐量、通信延迟与模型收敛速度。建议参考MLCommons的通信基准测试。
参考与信息来源
- 2026年5月:FPGA在AI集群中实现梯度压缩与通信加速,降低互联瓶颈(智能梳理/综述线索,无原文链接)。核验建议:关注NVIDIA GTC 2026相关演讲回放、MLCommons存储与通信工作组报告、以及IEEE Hot Interconnects会议论文。搜索关键词:FPGA gradient compression、collective communication offload。
- 2026年5月:边缘AI芯片转向FPGA+NPU异构集成,初创公司青睐灵活架构(智能梳理/综述线索,无原文链接)。核验建议:关注Embedded Vision Summit 2026、RISC-V峰会边缘计算分论坛。搜索关键词:FPGA NPU heterogeneous edge AI、adaptive inference accelerator。
技术附录
关键术语解释:
- 梯度压缩:在分布式训练中,通过减少梯度数据量(如只传输Top-K梯度)来降低通信开销。
- Top-K稀疏化:一种梯度压缩方法,只保留绝对值最大的K个梯度值,其余置零。
- All-Reduce:集合通信操作,用于在多个节点间汇总梯度并广播结果。
- NPU:神经网络处理单元,专为AI推理/训练设计的加速器。
- 异构SoC:在单个芯片上集成多种处理单元(如CPU、FPGA、NPU)的系统级芯片。
可复现实验建议:
- 使用Xilinx Vitis开发环境,在Alveo U250加速卡上实现Top-K梯度压缩模块,并与PyTorch分布式训练框架集成。
- 在Zynq UltraScale+ MPSoC上部署FPGA+NPU异构设计,FPGA负责图像预处理,NPU运行MobileNet推理。
边界条件与风险提示:
- FPGA梯度压缩加速的效果高度依赖模型与网络拓扑,对于小模型(如ResNet-50)可能收益有限。
- FPGA+NPU异构方案在量产前需通过严格的功耗与可靠性测试。
- 国产EDA工具与FPGA芯片的兼容性可能因版本而异,建议在官方论坛确认。
进一步阅读建议:
- 《FPGA-Based Accelerators for Deep Learning》—— Springer 2021
- Xilinx Vitis AI 开发文档
- RISC-V International 官方教程